%20(1)%20(1).png)

Customer data is the life blood of Product Led Growth (PLG) go-to-market (GTM) strategy. With data about your customers centralized in a data warehouse, you can provide them with the most relevant and proactive buying experience by leveraging everything you know about what they are doing in your product and combining that with the human-touch of your GTM teams. Without that data, you're stuck reaching out to customers based on a cadence that has zero insight into how your customers are using your product.
How many times have you received an email inviting you to “become a customer” when you already are one? Case in point.
However, becoming product-led can seem like an insurmountable challenge because… DATA!!! When we speak to potential customers, the common refrain is: but is my data ready? In this technical guide, we’ll share how we got our data ready here at Correlated so that we have insight into how our customers are using our product. Our sales and CS teams use this data to proactively reach out if something is going wrong, as well as to ensure that customers are getting the most value possible.
Identify the data your revenue team will need
This is a very important step, but it’s also a step that a lot of customers get stuck on. The reason is that teams feel pressured and obligated to get as much as they can out of the data team while they have them, so they try to boil the ocean on data! The truth is, data teams and GTM teams should expect to continue re-visiting the data they are exposing because businesses change, new features are built, and we learn new things every day.
What we did here was, we started out with the obvious things we wanted to track. Our focus as a company was to focus on onboarding customers successfully, so we decided to track everything involved in that onboarding process:
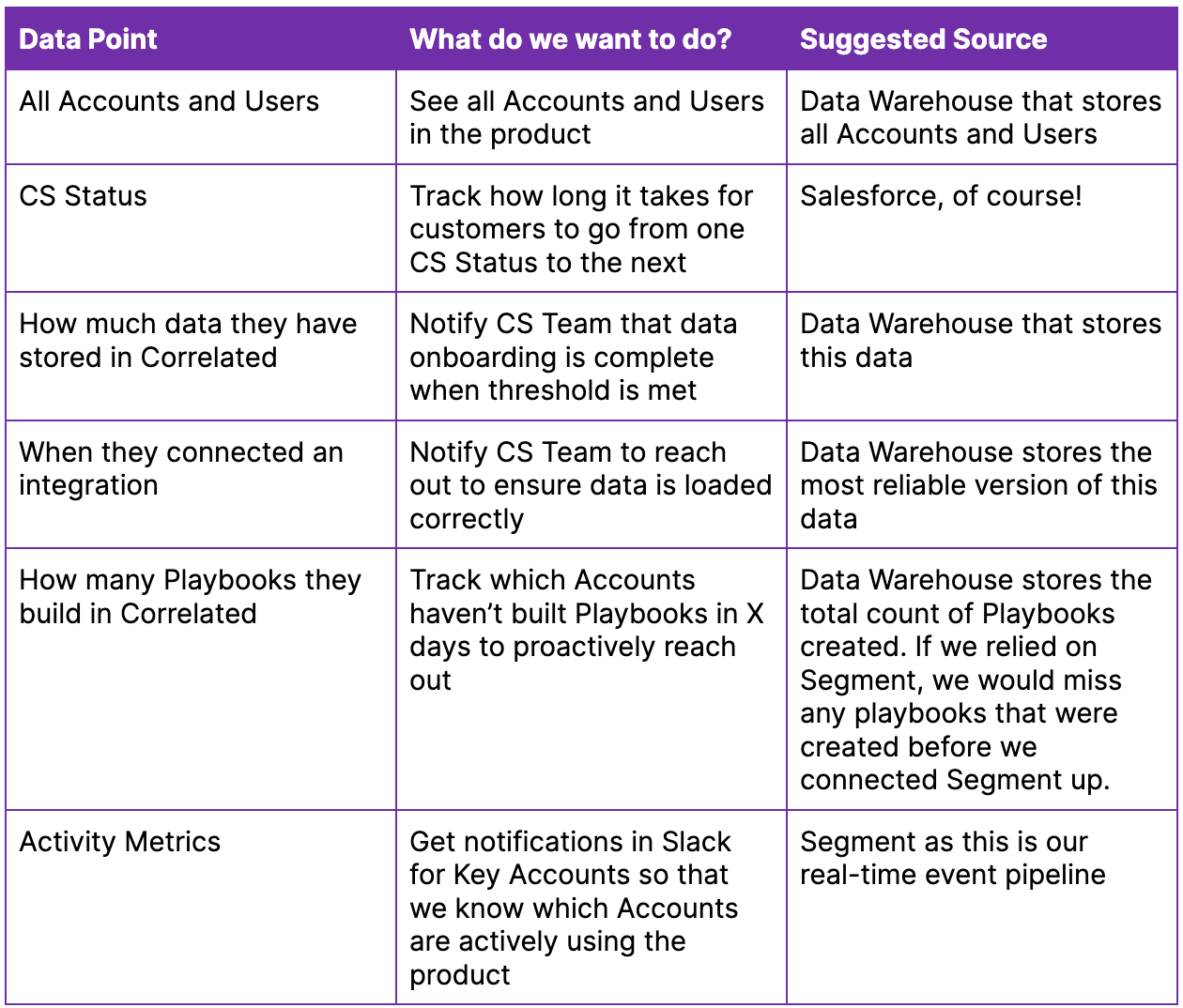
- All Accounts and Users
- Their CS Status in Salesforce
- How much data they have stored in Correlated
- When they connected an integration
- How many Playbooks they built in Correlated
- Activity metrics: Sign ins, button clicks for important features
Figure out where the data lives
Now that we’ve got a good checklist of data points we want, we can go through and figure out where to get the data. An important thing to think about here is that often, the same data can live in different data sources, and you want to choose the data source that matches best with how you anticipate using the data.
For example, let’s think about connecting an integration. We track integration success events in Segment and also store the timestamp of when an integration was created. Segment events are near real-time, but sometimes we get an integration success event that ultimately fails to actually create the integration, so it’s not very accurate. In our case, we wanted to use the data point to inform our CS team to reach out after each integration is connected for high-tier customers, so it was important for us to get this right.
In the table below, you can see how we went about picking and choosing which data source to use.
Make sure it’s possible to combine data sources
Here’s why data is so difficult for PLG - not only is there a lot of it (we addressed this problem by NOT boiling the ocean), it also lives in different places! As a result we suggest centralizing your data in a data warehouse, in our case BigQuery, to allow you to take action off of it by building playbooks.
The key to success here is to unify all your users and accounts with a unique ID.
What does this mean? Well, typically when an account or user comes into your product, they get assigned a UUID. This is what we recommend you use. This UUID should be what you use to identify your users in your data warehouse, and is also how you will join all the data you have about your users.
In our case, one data source does not have a UUID: Salesforce. Segment and our Data Warehouse use the same UUID because that is how we set up our infrastructure to track users as they come through our app. However, Salesforce data is often either manually entered by sales reps, or automatically entered via Marketing forms etc. There is no connection with product usage whatsoever!
Pipe CRM data into your data warehouse
The path we chose (and this is one that many of our customers choose too) was to pipe all of our Salesforce data into BigQuery (our data warehouse) so that we could transform it there. All of our Salesforce fields are individual columns in a table, and we have different tables for each object. For example, we have an Accounts table, Contacts table, Leads table, and Opportunities table. Now we can build whatever analysis we need, and it’s highly flexible! You can use an ETL tool to do this, although Segment also supports dumping Salesforce data into CDWs if you wanted to go with something lighter weight.
Getting all the data into a data warehouse is great, but we wanted to tag every Account and User in Salesforce with their unique ID because if we ever wanted to get product data into Salesforce, we would need it.
We created two mapping views: salesforce_mapping_accounts and salesforce_mapping_users.
Salesforce_mapping_accounts
This table matches account IDs to SFDC Account IDs by finding any users in the product who are a Contact in Salesforce and traversing to find the associated Account.
Schema:
accountId
orgName
SFDC_Account_ID

Salesforce_mapping_users
This table matches user IDs in the product to SFDC Contact IDs by matching on email. Notice that we don’t care about Leads, since our sales team doesn’t operate on Leads, only on contacts.
Schema:
userId
SFDC_Account_ID
SFDC_Contact_ID

Next, we use a reverse ETL solution, in our case, Hightouch, to take the joined accountID and userID and write it back into Salesforce in a custom field.
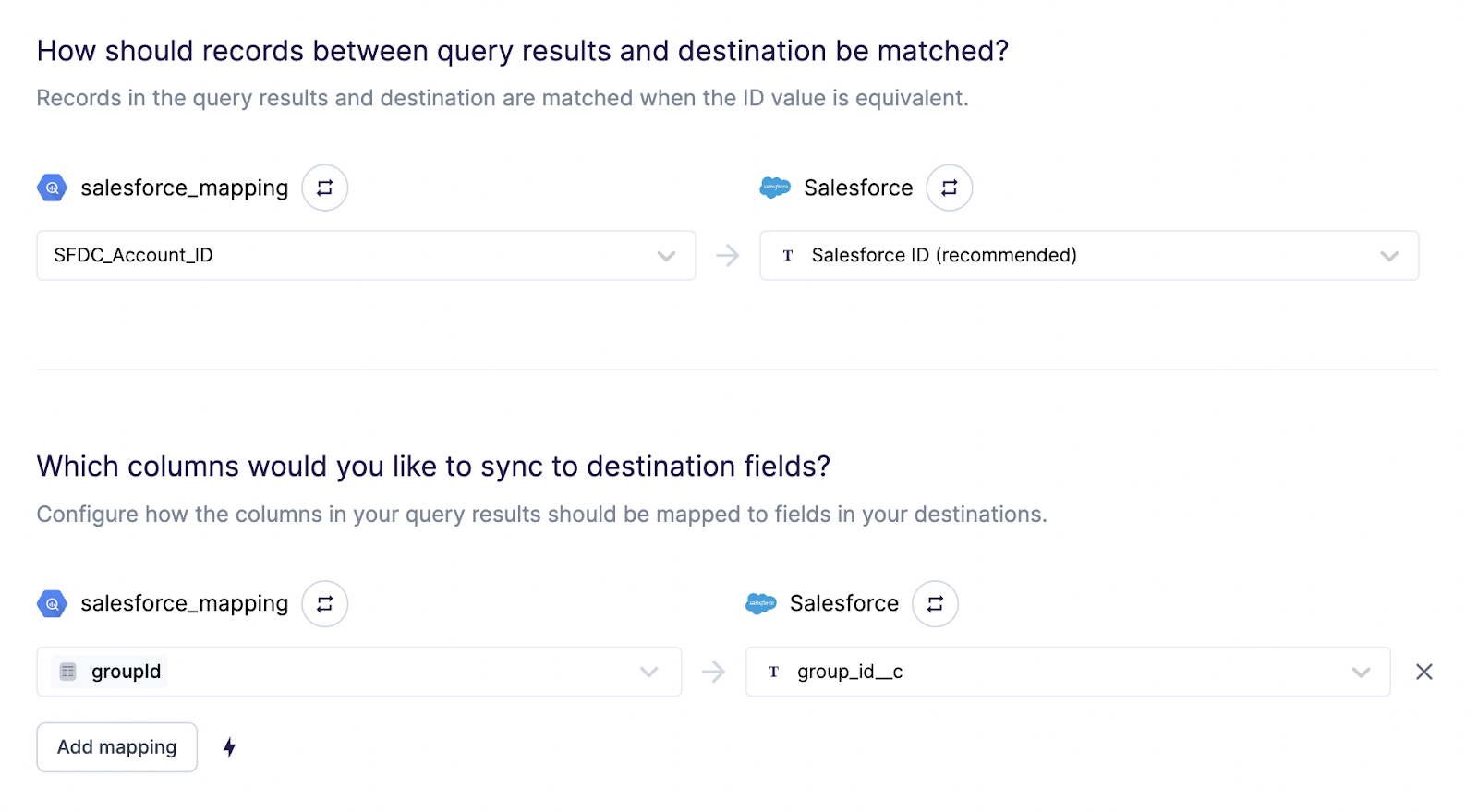
For Accounts, we created a custom “groupId” field in Salesforce, and linked things like this:
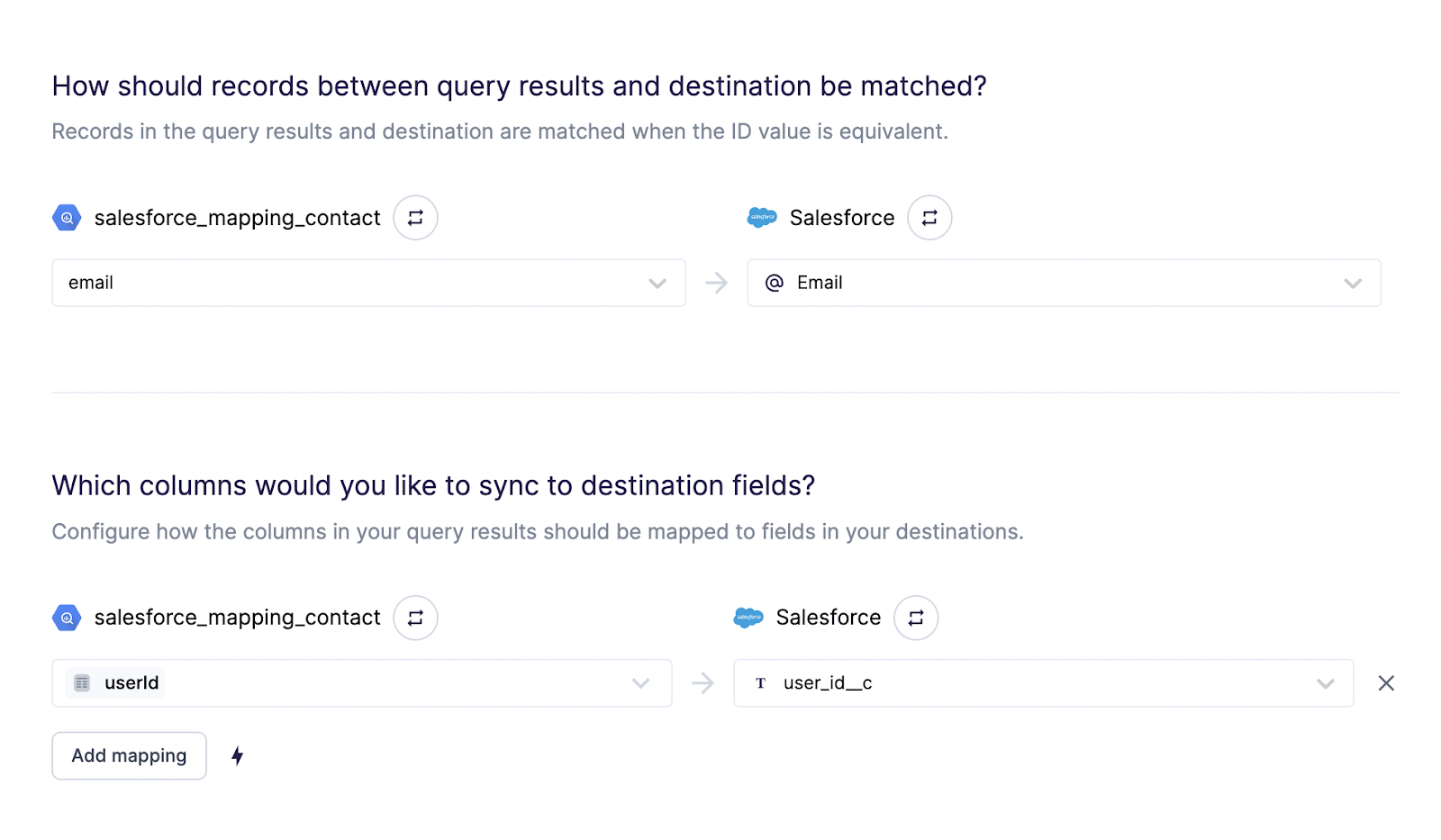
For Users, we created a custom “userId” field in Salesforce, and linked things like this:
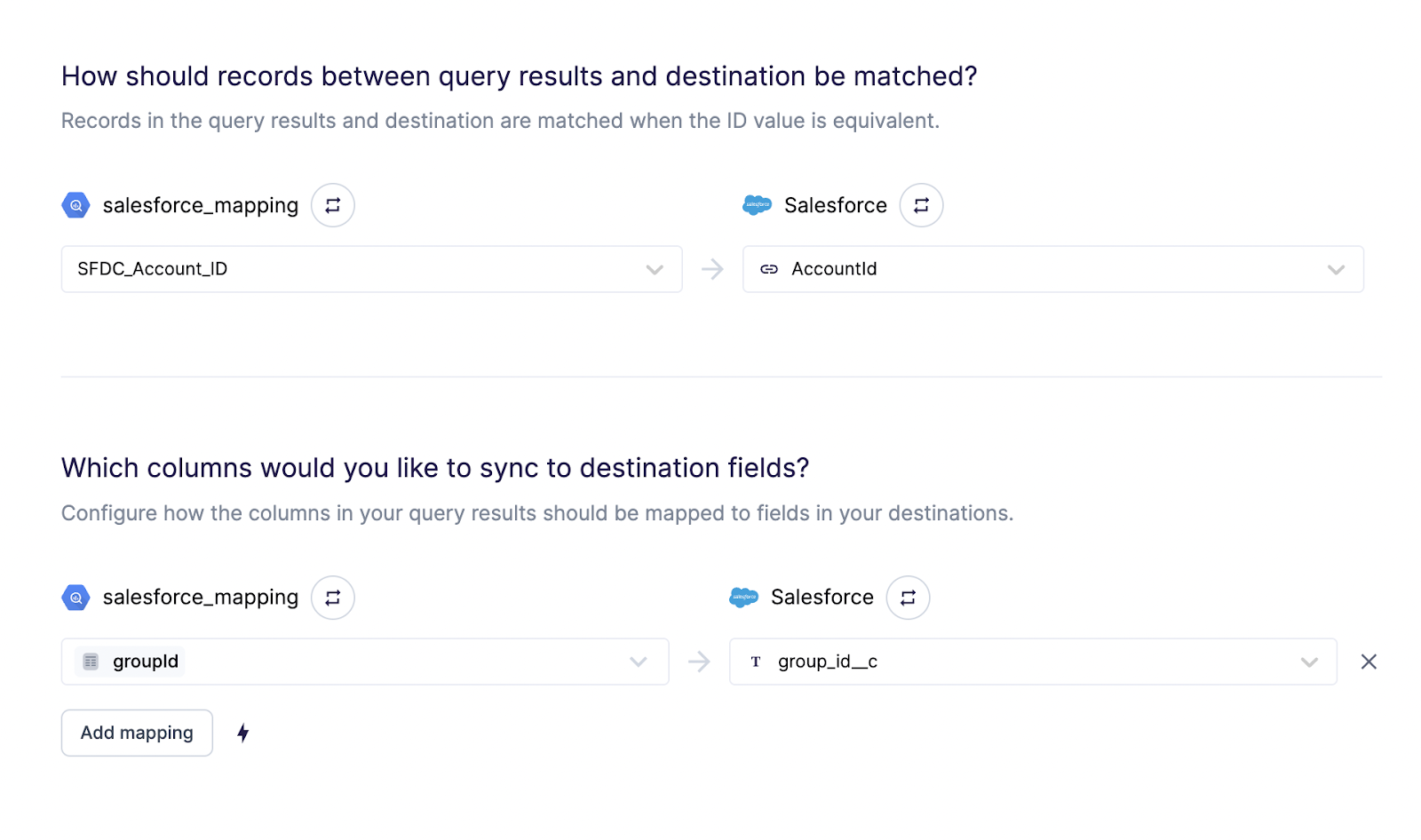
For Opportunities, we created a custom “accountId” field in Salesforce, and linked things like this:
Wow, that was a lot! Don’t worry - although it seems like a lot, creating the views and setting up Hightouch took me around 30 minutes to an hour.
Build the views you need in your data warehouse
With Salesforce set up with unique user IDs, you can further use Hightouch to pipe any additional data in your data warehouse that you want to expose to sales teams. However, BE PRUDENT. We’ve talked to customers who have literally tapped out on custom fields in Salesforce. This is no good, because then every incremental change you want to make to operationalize Salesforce becomes a huge headache. Also, you don’t want to flood your sales reps with data, you want to send them insights on how to sell and who to sell to.
This is where views come in. Views are great because you can expose them in BI tools, and you can also connect them to tools like Correlated.
Here are the views we built to expose the data points we cared about:
Accounts View
This view exposes all accounts, as well as the various data points we want to know about these accounts.
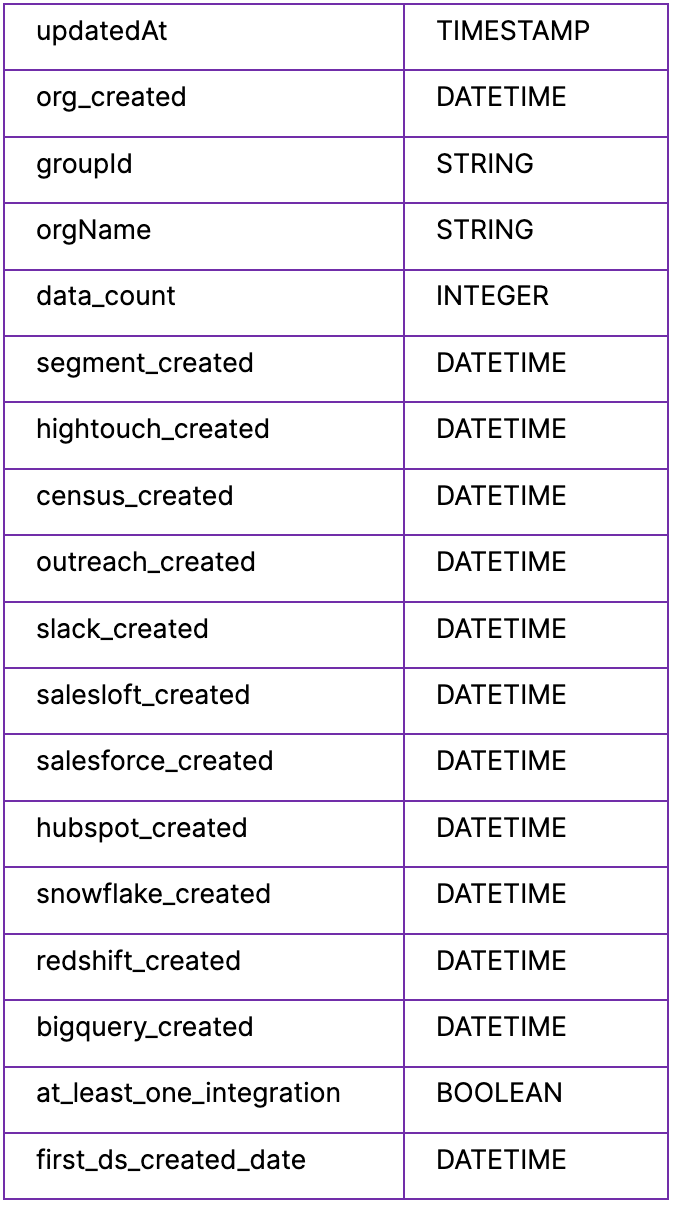
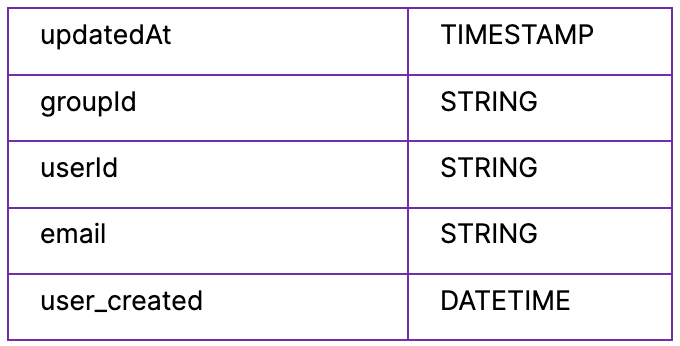
Users View
This view exposes all users, and helps us join users to accounts.
Workflows View
This view exposes the various playbooks that accounts have created.

Now with these three views, business teams are empowered to leverage new age PLG tools to better understand what customers are doing in the product so that they can provide a better buying experience.
Next step: Apply what you’ve learned
If you’re an early stage startup, you might think that you are “too early” for some of these suggestions. That may very well be true, and many early stage companies get very far with just Segment and a CRM (or some other alternatives). However, you should always keep in the back of your mind that the data warehouse is likely a “when” not “if” as there will always be product data that does not live in Segment, and there will always be a need to transform and join product and CRM data.
If you’re a larger company, you’ve likely already done this! If you aren’t using dbt, I’d also highly recommend that. We hit a bunch of issues because we weren’t using dbt that we're now solving thanks to dbt. We'll do a future blog post on how to properly set-up dbt for PLG. My only other suggestion would be to look at the schema examples to get a feel for the views that SaaS apps like Correlated need in order to get you to success. With defined schemas, you’ll be able to build one view that can support sales, customer success, and marketing in a much more scalable fashion. In fact, Correlated supports a checkbox self-onboarding data selector that even business teams can use to import existing views from data warehouses into Correlated.
If you’re interested in learning more, you can Get Started today. Otherwise, head over to our PLG Resource Hub where you can see some examples of how product data can really allow for a completely re-imagined PLG GTM workflow.

.jpg)

